

SC23 exhibits in Denver, CO, November 13 - 16, 2023
Nagoya University Information Technology Center made an exhibit at SC23,
the International Conference for High Performance Computing, Networking, Storage and Analysis in Denver, Colorado.
Short talks were presented at the Nagoya University booth.
- Exhibition: November 13 - 16, 2019.
- Conference: November 12 - 17, 2019.
- Nagoya University Booth: #1970
Overview
In an information society with advanced information and communication technologies, a university must be "a campus where information support is provided to all university activities" and a demand for enhancing this environment is strong. In order to stimulate education and research, it is essential to use, support and disclose information, while the forms of technology and service are rapidly becoming more advanced and complicated.
Nagoya University Information & Communications (IC) was established on April 1, 2006 as a central organization for resolving the issues mentioned above and the aim of Information & Communications is to facilitate the integration and streamlining of execution and service systems by planning the University's information strategy. On April 1, 2009, as the final step in the development of this organization, we established the Information Technology Center (ITC) as part of Information & Communications. The former Information Technology Center and the Center for Information Media Studies have been fully merged in order to enhance the functioning of our Information Strategy Office and to give strong support to high-tech and practical research.
The Information Technology Center, as part of the Information & Communications, Nagoya University, cooperates with the Information Strategy Office, Information Security Office and the Information Promotion Department in order to take responsibility for the development and stable operation of the information infrastructure. including supercomputers and networks for education and research at Nagoya University. The Information Technology Center also plays a role in the research and development of High Performance Computing technology in Japan as part of the Joint Use/Research Center for Interdisciplinary Large-Scale Information Infrastructures which consists of eight facilities, including the Information Technology Centers of seven largest national universities in Japan and the Tokyo Institute of Technology Global Scientific Information and Computing Center. They were originally National Joint-Use Facilities, became Joint Use/Research Centers during the last fiscal year and they provide not only support for users, but also engage in joint national research in cooperation with the Information Technology Centers of the eight universities.
Booth Talks
Monday, 13 November 2023 (In Opening Gala)
- 19:15-19:30 Hiroyuki Takizawa (Tohoku University)
- "Performance evaluation of modern vector processors with high bandwidth memory"
Abstract: Tohoku University Cyberscience Center has just started operation of Supercomputer AOBA-1.5, which employs the 3rd generation SX-Aurora TSUBASA vector computing system as the main computing resource. This talk introduces our performance evaluation results of the modern vector computing system on SPEChpc benchmarks and practical applications. In addition, we are actively working to expand the applicable areas of the vector computing technologies, from numerical simulations to big data analysis.
- "Performance evaluation of modern vector processors with high bandwidth memory"
- 19:30-19:45 Osni Marques (Lawrence Berkeley National Laboratory )
- "Massively Parallel Eigensolvers Based on Minimization Strategies"
Abstract: This presentation will summarize work in unconstrained schemes strategies for the solution of eigenvalue problems in electronic structure calculations. These schemes employ a preconditioned conjugate gradient approach that avoids an explicit reorthogonalization of the trial eigenvectors, in contrast to typical iterative eigensolvers, therefore reducing communications and becoming attractive for the solution of very large problems on massively parallel computers. The presentation will also discuss the need to rearrange calculations and FFTs to achieve performance, in particular on GPUs.
- "Massively Parallel Eigensolvers Based on Minimization Strategies"
- 19:45-20:00 Takeshi Fukaya (Hokkaido University)
- "Numerical Investigation of Mixed Precision Sparse Solvers using low precision computing"
Abstract: Exploiting low precision computing in the filed of numerical linear algebra is one of important tasks because the performance improvement of double-precision floating-point number (FP64) on recent hardware is difficult. In this study, for a linear system with a sparse, large, and non-symmetric coefficient matrix, we develop a mixed precision (MP) method that uses low precision computing in dominant computation and provides a solution as accurate as that by a conventional method. Our method is based on a mixed precision variant of iterative refinement (MP-IR), and we consider two candidates of Krylov method as an inner solver used in MP-IR, namely the GMRES and BiCGSTAB methods. We implement the two methods, namely MP-IR using GMRES and MP-IR using BiCGSTAB, by combining FP64 and FP32 and conduct numerical experiments on a standard CPU platform to investigate their characteristics and effectiveness. In our talk, we present the outline of our developed methods and highlights of the experimental results. This is joint work with Yingqi Zhao and Takeshi Iwashita.
- "Numerical Investigation of Mixed Precision Sparse Solvers using low precision computing"
Tuesday, 14 November 2023
- 13:15-13:30 Franz Franchetti (Carnegie Mellon University)
- "Updates on SPIRAL and LibraryX"
Abstarct: In this talk we present an update on SPIRAL and the LIbraryX framework enabled by it. We briefly discuss the X-libraries FFTX, PROTOX, GBTLX, and NTTX implemented as eDSLs (embedded domain specific languages/libraries) in C++ as well as their instantiation as plugins for LLVM/CLANG/FLANG, C++ Python and Julia. We discuss how the LibraryX framework and SPIRAL's capabilities can be utilized for developing domain-specific accelerators and the associated software stack. Finally, we discuss how LibraryX can be used in the context of generative AI to "police" systems like ChatGPT and CodePilot to ensure correctness of the implementation returned by these systems.
- "Updates on SPIRAL and LibraryX"
- 13:30-13:45 Tetsuya Hoshino (Nagoya University)
- "Performance Evaluations of Temporal Blocking on Modern Multi-core CPUs"
Abstract: Temporal blocking is known as an effective optimization method for stencil calculations, a calculation pattern that frequently appears in computational fluid dynamics simulations. Since the performance obtained by temporal blocking is highly dependent on the performance balance of the hardware, it is not clear what performance can be obtained on the latest multi-core CPUs with large shared caches or HBM. In this presentation, we evaluate the performance of temporal blocking techniques on A64FX and Sapphire Rapids with HBM, and Intel Xeon and AMD EPYC CPUs with large shared caches.
- "Performance Evaluations of Temporal Blocking on Modern Multi-core CPUs"
- 13:45-14:00 Takahiro Katagiri (RIKEN R-CCS / Nagoya University)
- "Towards new auto-tuning technology for next-generation supercomputers: from AI to quantum-related technologies"
Abstract: In recent years, significant strides have been made in AI technology, primarily spurred by the advent of large-scale language models (LLMs). Conversely, fundamental research into harnessing the power of quantum computers for high-performance computing platforms is rapidly gaining traction. While these two fields may appear distinct, their underlying technologies are interconnected. This relationship bears relevance, especially in the evolution of next-generation supercomputer systems. It is noteworthy that both domains inherently possess "parameters" that wield influence over performance. Moreover, the fine-tuning of these parameters is imperative for achieving peak performance. In this presentation, we aim to provide a comprehensive overview of auto-tuning (AT) technology, recognized as a pivotal factor in the forthcoming development of next-generation computers.
- "Towards new auto-tuning technology for next-generation supercomputers: from AI to quantum-related technologies"
Wednesday, 15 November 2023
- 13:30-13:45 Yohei Miki (The University of Tokyo)
- "Performance evaluation of N-body code on NVIDIA H100 PCIe and AMD MI210"
Abstract: Recent competition among GPU vendors has driven GPU performance improvements. Vendors advertise the performance of their products; however, scientists in various fields should verify the actual performance in scientific simulations. We have developed gravitational N-body codes based on the direct method and have optimized for recent NVIDIA and AMD GPUs. Detailed performance evaluation reveals that (1) NVIDIA H100 PCIe is 2.0x faster than NVIDIA A100, (2) AMD MI210 is 1.4x faster than AMD MI100, and (3) both GPUs are 1.5x more power-efficient than their predecessors. We will discuss the origin of the observed speedup and the discrepancy with the ratio of the theoretical peak performance.
- "Performance evaluation of N-body code on NVIDIA H100 PCIe and AMD MI210"
- 13:45-14:00 Satoshi Ohshima (Kyushu University)
- "BLR-QR on GPU using MPS and MIG / How to utilize thousands of GPU cores?"
Abstract: Current GPUs have massively parallel computation cores, but various applications don't have enough parallelism to fill the cores. In order to obtain high performance reasonably, we focus on the utilization of MPS and MIG features of GPU. We have confirmed the positive result on QR decomposition of Block Low Rank matrix (BLR-QR). We show the current status of the work.
- "BLR-QR on GPU using MPS and MIG / How to utilize thousands of GPU cores?"
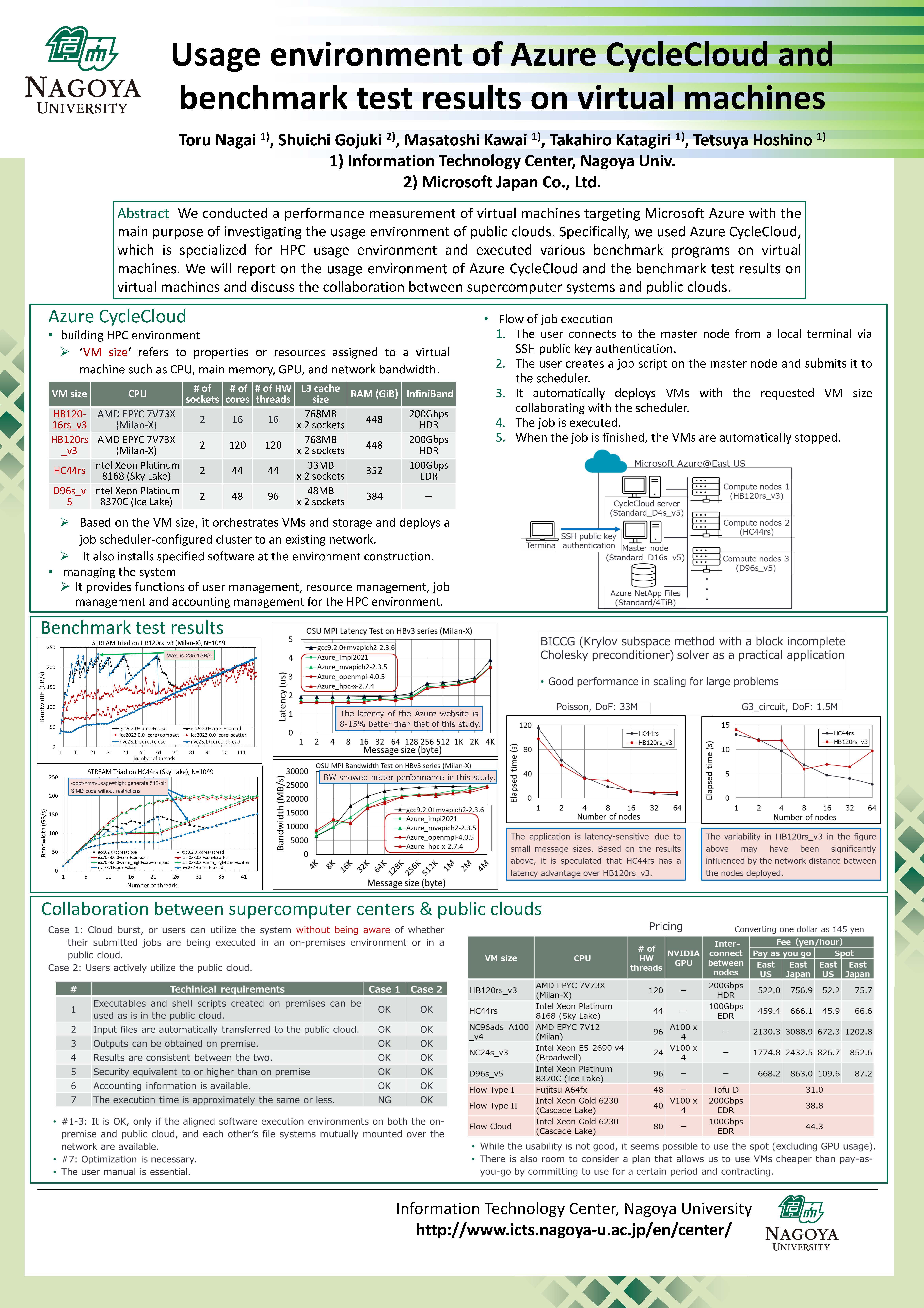
- 14:00-14:15 Toru Nagai (Nagoya University)
- "The usage environment of Azure CycleCloud and benchmark test results on virtual machines"
Abstract: We conducted a performance measurement of virtual machines targeting Microsoft Azure with the main purpose of investigating the usage environment of public clouds. Specifically, we used Azure CycleCloud, which is specialized for HPC usage environment, under the joint research of Nagoya University Information Infrastructure Center and Microsoft Japan, and executed various benchmark programs on virtual machines. In the talk, the speaker will report on the usage environment of Azure CycleCloud and the benchmark test results on virtual machines, and discuss the collaboration between supercomputer systems and public clouds.
- "The usage environment of Azure CycleCloud and benchmark test results on virtual machines"
- 14:15-14:30 Yuki Satake (Hokkaido University)
- "Tensor product structure preserving preconditioners for matrix equations"
Abstract: In this talk, we consider iterative methods for solving linear matrix equations. For linear systems, there are many existing preconditioning techniques. However, most of them disrupt the tensor product structure of the coefficient matrix of the matrix equation, which increases the memory requirements. We propose memory-saving preconditioners for matrix equations by preserving the tensor product structure.
- "Tensor product structure preserving preconditioners for matrix equations"
Posters at SC23 Exhibits
 |
 |
 |
| History of ITC-NU | Supercomputer system | HPCI and JHPCN |
 |
 |
 |
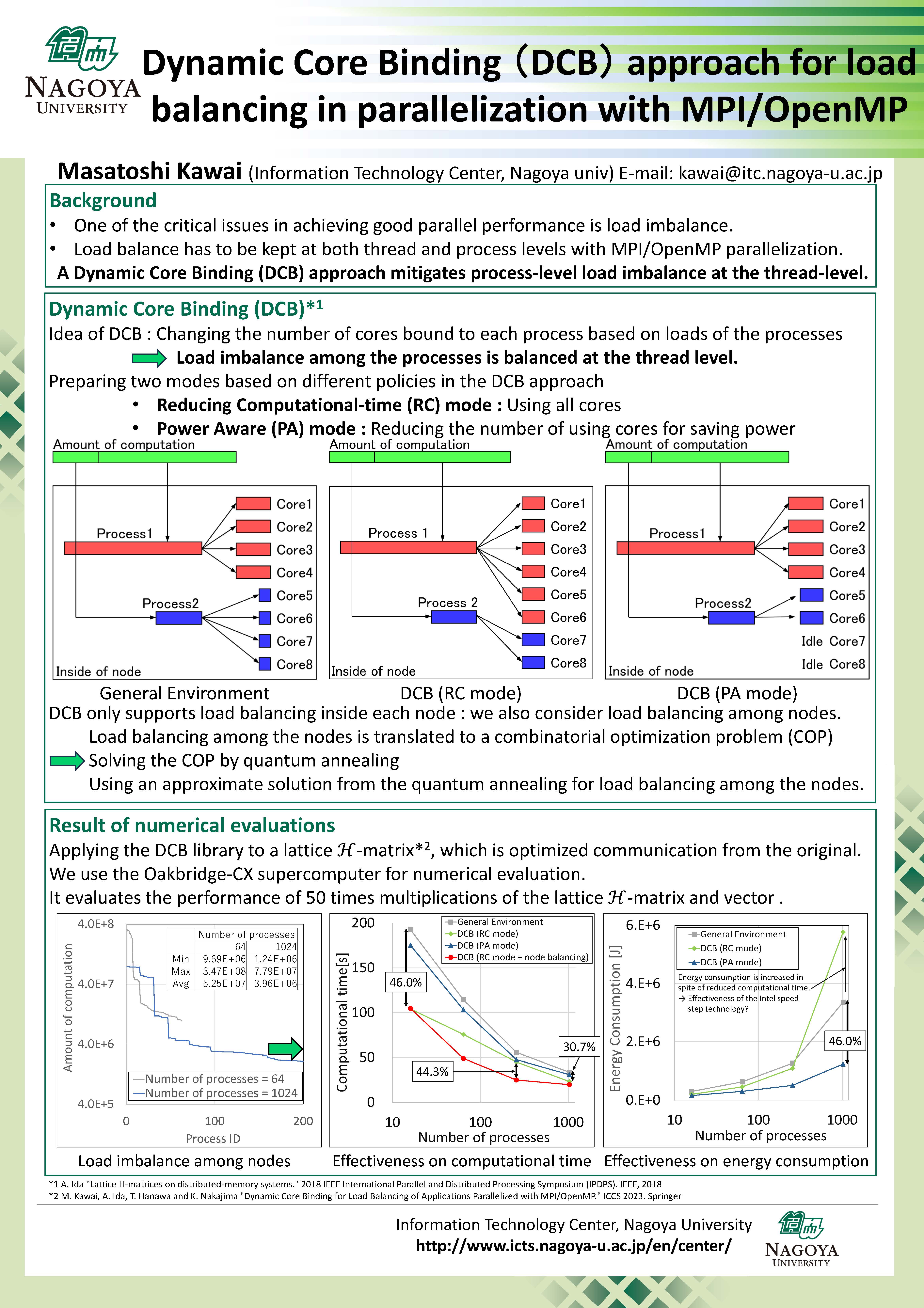 |
| Feasibility Studies on Next-Generation Supercomputing Infrastructures: System Software and Library Research | Optimizations of ℋ-matrix-vector Multiplication for Modern Multi-core Processors | Usage environment of Azure CycleCloud and benchmark test results on virtual machines | Dynamic Core Binding (DCB) approach for load balancing in parallelization with MPI/OpenMP |