



国際会議SC24における展示
情報連携推進本部および情報基盤センターでは,共同研究・共同利用拠点の提供計算機資源, サービス業務,および研究活動のアウトリーチを目的として, 2024年11月17日~22日米国ジョージア州アトランタで開催された 国際会議SC24にて展示を行いました.
・展示期間:2024年11月18日~21日
・展示ブース:♯3839
ショートトークのスケジュール
Monday, 18 November 2024 (In Opening Gala)
- 19:15-19:30 Hiroyuki Takizawa (Tohoku University)
- "Realizing Connected Supercomputing with dynamic and adaptive resource management"
Abstract: AOBA is the world's largest vector computing system installed at the Cyberscience Center, Tohoku University. We are now trying to connect the AOBA system to various kinds of external data sources and real-world information. We advocate "Connected Supercomputing" which is to enable a supercomputing system for academic use to timely respond to external factors connected to the system. For Connected Supercomputing, we must develop new operation policies as well as the system software for dynamic and adaptive resource management. In this talk, I will introduce the AOBA system and then some recent research activities for realizing Connected Supercomputing.
- "Realizing Connected Supercomputing with dynamic and adaptive resource management"
- 19:30-19:45 Franz Franchetti (Carnegie Mellon University)
- "SPIRAL: LibraryX and Communication Avoiding Convolutions"
Abstract: In this talk we present an update on SPIRAL and the LibraryX framework enabled by it. We briefly discuss the X-libraries FFTX and PROTOX, as well as how to convert legacy libraries like FFTW and C++ STL into X-libraries. We also introduce FortranX, an X-library plugin for GNU Fortran. Further, we give an initial glimpse at communication-avoiding techniques applied to spectral PDE solvers like Poisson solvers. The hope is that our approach can keep N log N (FFT based convolution) algorithms competitive in the era of supercomputers with multi-accelerator fat nodes with tensor cores optimized for DGEMM.
- "SPIRAL: LibraryX and Communication Avoiding Convolutions"
- 19:45-20:00 Takeshi Fukaya (Hokkaido University)
- "Recent progress in CholeskyQR-type algorithms for QR factorization of tall and skinny matrices"
Abstract: The QR factorization of tall and skinny matrices is a fundamental building block in numerous scientific and engineering applications. In this talk, we focus on CholeskyQR-type algorithms, which are well-suited for high-performance computing. Recent advances in the development of these algorithms will be presented, with benchmark results on supercomputer systems in Japan.
- "Recent progress in CholeskyQR-type algorithms for QR factorization of tall and skinny matrices"
Tuesday, 19 November 2024
- 13:00-13:15 Satoshi Ohshima (Kyushu University)
- "BLR-QR on Supercomputer Genkai"
Abstarct: GPUs are hardware that achieves high performance through parallel computation using many computation cores. Therefore, it is difficult to achieve sufficient performance with low parallelism. We are working on speeding up QR decomposition of Block Low-Rank matrix (BLR-QR). This program performs block-wise computation, but block-wise computation is not a good computation for GPUs because it does not have a high degree of parallelism. Therefore, we have been working on improving the performance of BLR-QR by using the MIG feature of recent NVIDIA GPUs. In this presentation, we introduce the implementation and performance evaluation of BLR-QR on the new supercomputer GENKAI of Kyushu University.
- "BLR-QR on Supercomputer Genkai"
- 13:15-13:30 Takeshi Iwashita (Kyoto University)
- "An Integer Arithmetic-Based Sparse Linear Solver Using a Preconditioned GMRES Method"
Abstarct: In this talk, a research activity on an integer arithmetic-based sparse linear solver is introduced. The research started in 2019 and its first result was reported in the SC|20 workshop (ScalA). We developed a (preconditioned) GMRES solver based on integer arithmetic and an iterative refinement framework for the solver. We defined the data format for the coefficient matrix and vectors for the solver that is based on integer or fixed-point numbers. To avoid overflow in calculations, we introduced initial scaling and shifts (adjustments) of operands in arithmetic operations. We proposed the approach for operand shifts, considering the characteristics of the GMRES algorithm. Numerical tests demonstrated that the integer arithmetic-based solver with iterative refinement had comparable solver performance in terms of convergence to the standard solver based on floating-point arithmetic. In the talk, the recent progress of the research on multigrid preconditioning is also introduced.
- "An Integer Arithmetic-Based Sparse Linear Solver Using a Preconditioned GMRES Method"
- 13:30-13:45 Tomohiro Umeda, Wataru Tokuchi, Akihiro Fujii, Teruo Tanaka (Kogakuin University), Takumi Washio (The University of Tokyo)
- "Analysis of the Random Force Correction Method using Cholesky Decomposition Semi-implicit Solutions of the Overdamped Langevin Equation"
Abstract: This study introduces a semi-implicit method with random force correction to solve the overdamped Langevin equation with large time steps. Simulations on a one-dimensional mass-spring model showed that this correction method closely matches the mean and standard deviation of reference data from an explicit method with small time steps. We investigated Cholesky and incomplete Cholesky decompositions for random force correction, finding that while Cholesky preserved accuracy, incomplete Cholesky reduced convergence speed.
- "Analysis of the Random Force Correction Method using Cholesky Decomposition Semi-implicit Solutions of the Overdamped Langevin Equation"
- 13:45-14:00 Shinji Sumimoto (The University of Tokyo)
- "Hierarchical, Hybrid, Heterogeneous Center-wide Computing using WaitIO"
Abstract: This talk presents a system-wide communication library to couple multiple MPI programs for heterogeneous coupling computing called h3-Open-SYS/WaitIO (WaitIO for short). WaitIO provides an inter-program communication environment among MPI programs and supports different MPI libraries with various interconnects and processor types. This talk shows the basics of WaitIO and the application examples with JSC collaboration and related projects including the JHPC-quantum project which aims to realize QC-HPC hybrid computing.
- "Hierarchical, Hybrid, Heterogeneous Center-wide Computing using WaitIO"
- 19:00- Nagoya U. Booth Presenters Party
Cuts Steakhouse
60 Andrew Young International Blvd NE, Atlanta, GA 30303
Name: TAKAHIRO KATAGIRI Confirmation #: 2110026547
Wednesday, 20 November 2024
- 13:30-13:45 Susumu Date (Osaka University)
- "RED ONION - High-speed Data Transfer Service on Campus to Supercomputing system"
Abstract: Osaka University has been working on the research and development of data transfer service named RED ONION (Research EnhanceD Osaka university Next-generation Infrastructure for Open research and Open innovatioN) that facilitates the users of our supercomputing system to utilize data generated on campus. In this talk we would like to introduce background and aim of our activities towards aggregation of computing infrastructure and data infrastructure and show some research results related to RED ONION.
- "RED ONION - High-speed Data Transfer Service on Campus to Supercomputing system"
- 13:45-14:00 Keita Teranishi (Oak Ridge National Laboratory)
- "JACC: Leveraging Performance Portability with the Just-in-Time Julia Language"
Abstract: We present JACC as a performance-portable meta-programming model for the just-in-time Julia language. JACC provides a unified and lightweight front end across different back ends available in Julia (Base.Threads, CUDA, AMDGPU, and OneAPI) to enable the same Julia code to run on different CPU and GPU targets. We evaluated the performance of JACC for common HPC kernels (e.g., AXPY, DOT, Conjugate Gradient algorithm, lattice-Boltzmann method) on modern HPC architectures found in some of the most advanced supercomputers today, including Frontier, Aurora, and Perlmutter equipped with a variety of architectures from different vendors—including AMD EPYC 7742 Rome CPUs, AMD Mi100 GPUs, NVIDIA A100 GPUs, and Intel Max 1550 GPUs. We show that the proposed programming model incurs only a negligible overhead versus Julia’s vendor-specific solutions. We report speedups for the GPU implementations over the CPU implementations with no extra cost to programmability for the kernel granularity.
- "JACC: Leveraging Performance Portability with the Just-in-Time Julia Language"
- 14:00-14:15 Yuga Yajima, Akihiro Fujii, Teruo Tanaka (Kogakuin University)
- "Proposal for A Parallel Automatic Tuning Using d-Spline According to The Operating State of The Computer System"
Abstract: Software auto-tuning (AT) is a technology that parameterizes factors that affect performance as "performance parameters" and automatically tunes performance. In AT, the tool searches for better values for performance parameters by repeatedly running the program. Therefore, if the target is a program with long execution times, such as machine learning, AT will take a very long time. For this problem, we have tried to reduce the time by running the target program in parallel. However, simple parallelization does not always take full advantage of the parallelism of the computer system. In this study, we proposed the system-resource-based search. This method increases the number of execution targets, and the system does not have excess computing resources. The system-resource-based search was independent of the size of the search space and made the best use of the computational resources available on the supercomputer.
- "Proposal for A Parallel Automatic Tuning Using d-Spline According to The Operating State of The Computer System"
- Osni's party
*19:30-22:00, November 20 (Wednesday), 2024
Fogo de Chao
3101 Piedmont Rd, Atlanta, GA 30305
SC24展示ポスター
 |
 |
 |
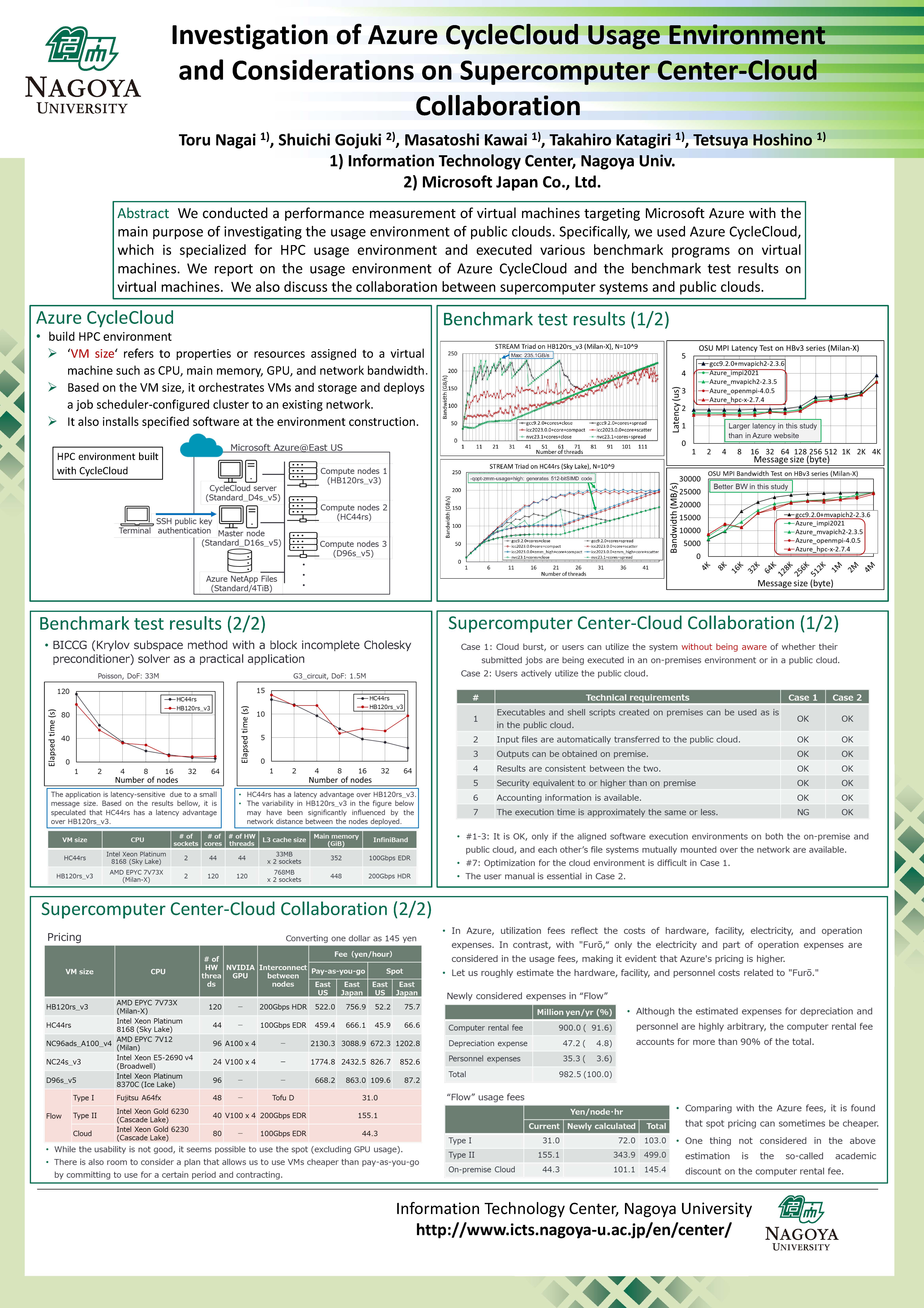
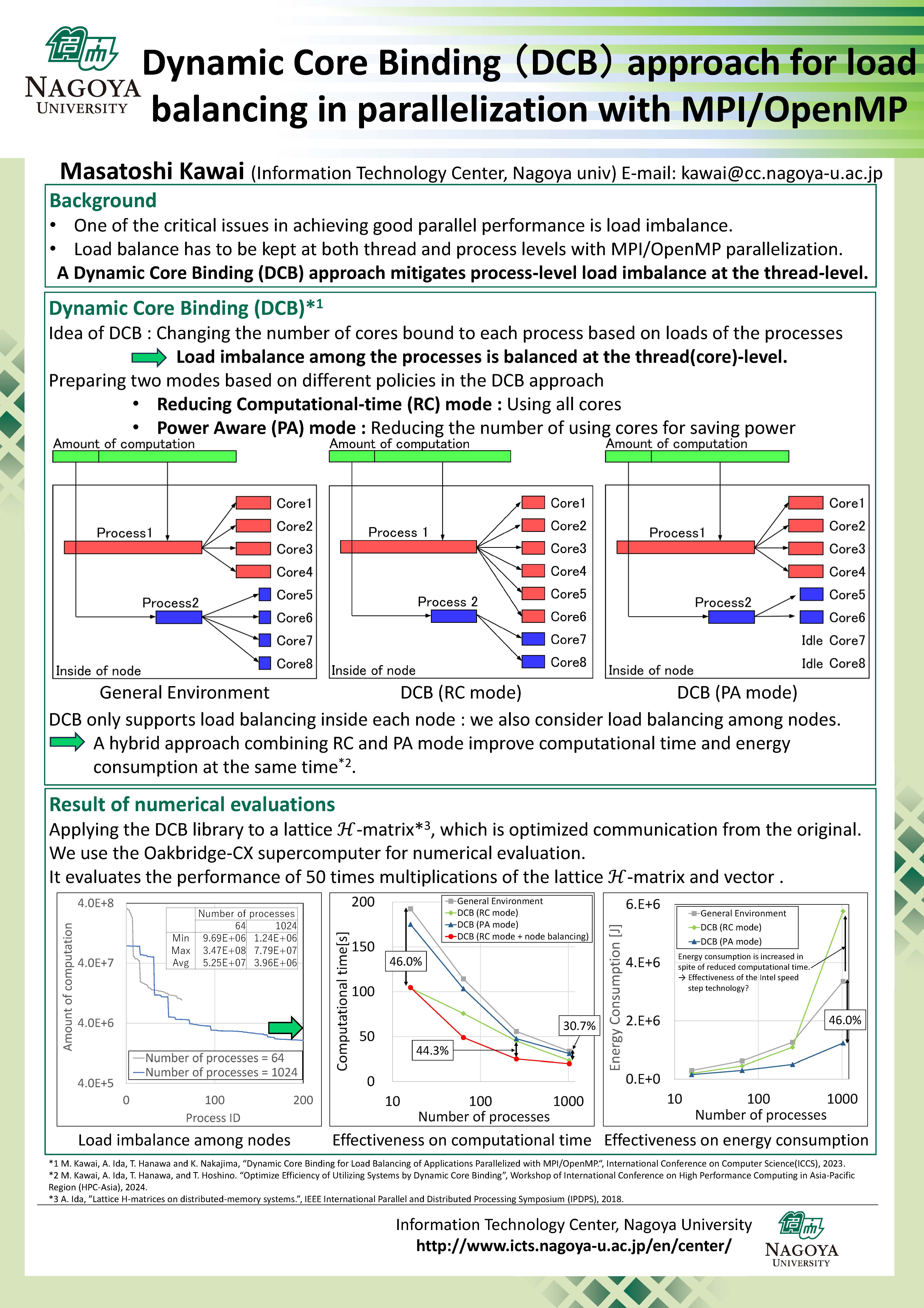
| History of ITC-NU | Supercomputer "Flow" system overview | HPCI and JHPCN |
 |
 |
 |
 |
| - Feasibility Studies on Next-Generation Supercomputing Infrastructures: System Software and Library Research
- Auto-tuning for Quantum-Inspired Annealing |
Optimizations of ℋ-matrix-vector Multiplication for Modern Multi-core Processors | Investigation of Azure CycleCloud Usage Environment and Considerations on Supercomputer Center-Cloud Collaboration | Dynamic Core Binding (DCB) approach for load balancing in parallelization with MPI/OpenMP |